






Mit der Entwicklung der Anwendungen kommt der Moment, in dem die Nachfrage nach einer genaueren Analyse dessen, was unser System derzeit tut oder in der Vergangenheit gemacht hat, steigt. Das Problem beginnt, wenn wir uns mit verteilter Architektur beschäftigen. In dieser Situation befinden sich die einzelnen Elemente unseres Systems meistens auf verschiedenen Maschinen, was die Analyse der Probleme oft erschwert.
Wenn unser System an Popularität gewinnt, müssen wir darüber nachdenken, wie die einzelnen Elemente effektiv überwacht werden können. Oft unterschreiben wir Verträge wie SLA (Service Level Agreement), die uns zu einer gewissen Verfügbarkeit unserer Dienstleistungen zwingen. Ein Verstoß gegen diese Vereinbarungen ist oft mit unangenehmen, oft finanziellen Folgen verbunden. Die Nichteinhaltung eines angemessenen Zugangsniveaus hat häufig zur Zerstörung verschiedener Organisationen geführt. Wir müssen schnell auf Anomalien, Unterbrechungen beim Betrieb einzelner Dienste reagieren. Es ist entscheidend, die Ursache des Ausfalls zu ermitteln und sie schnell zu beseitigen.
Eine der Methoden zum Überwachen und Ermitteln der Fehlerursachen im Systembetrieb ist die Analyse des Anwendungslogs. Und das werden Sie aus diesem Artikel erfahren.
Überlegen Sie kurz, wie wir das Thema der Organisation von Logs unseres Systems problemlos angehen können. Wie ich bereits erwähnt habe, besteht die Chance, dass unser System auf mehreren (und sogar mehreren hundert) physischen Maschinen verteilt wird. Was ist, wenn wir nicht möchten, dass das IT-Team einen direkten Zugriff auf einzelne Maschinen hat? Wir können dann einen Ort organisieren, an den wir unsere Anwendungslogs von den angegebenen Servern umleiten und dem Team Zugriff gewähren. Dieser Ansatz funktioniert bis zu einem gewissen Punkt. Leider löst er nicht das Problem der verteilten Informationen, die den Wert bei der Gesamtanalyse liefern.
Mit Hilfe kommt ELK Stack: Elasticsearch, Logstash, Kibana also eine Reihe von Tools zur Verarbeitung von Anwendungslogs und zur deren zentralen Verwaltung. ELK besteht aus:
- Elasticsearch – eine Datenbank, in der unsere Logs gespeichert werden, sie bietet einen schnellen Zugriff auf Informationen, die uns interessieren.
- Logstash – ein Werkzeug, zu dem unsere Logs von verschiedenen Maschinen ankommen, um sie zu verarbeiten und wichtige Informationen von uns zu gewinnen. Logstash kommuniziert mit der Datenbank, um verarbeitete Logs zu speichern.
- Kibana – ein Werkzeug zur Visualisierung von Daten aus der Elasticsearch-Datenbank.
ELK wird unter einer gemeinsamen Version veröffentlicht, was bedeutet, dass zum Beispiel die Verwendung von Elasticsearch in Version 6.5 zwingt uns, dass andere Tools mit dieser Versionsnummer gekennzeichnet sein müssen.
Schauen wir uns zuerst das Tool an, das unsere Logs direkt verarbeitet – Logstash. Mit Logstash können Sie einen bestimmten Workflow erstellen, auf dessen Grundlage die dazugehörigen Logs einheitlich verarbeitet und umgewandelt werden können. Es enthält eine Reihe von Funktionen und grundlegenden Bedingungsanweisungen, die dazu dienen, bestimmte Muster in unseren Logs zu erkennen und mit zusätzlichen Informationen anzureichern.
Die grundlegende Logstash-Konfigurationsdatei ist die Datei logstash.conf. Sie enthält drei grundlegende Abschnitte, die wir mit den Ausdrücken ergänzen, an denen wir interessiert sind.
input {}
filter {}
output {}
Der Abschnitt input definiert den Eingang zum Logstash. Er stellt eine Reihe von Plugins bereit, die die Integration mit verschiedenen Informationsquellen ermöglichen, z.B.:
- Kafka – liest die Ereignisse aus einem bestimmten Thema des Nachrichtenbrokers von Kafka,
- Log4j – liest Daten direkt aus der Anwendung, in der der TCP-Socket konfiguriert ist, über den Log4J Anwendungslogs überträgt,
- File – wird verwendet, um Daten aus einer Datei zu streamen.
Sobald wir eine konfigurierte Methode zum Eingang von Daten haben, ist es an der Zeit, sie zu verarbeiten. Die grundlegenden Plugins für den Abschnitt filter sind:
- Grok – ein sehr nützliches Plugin, mit dem Logs analysiert und in die entsprechenden Felder eingefügt werden,
- Date – wird verwendet, um Datumsangaben zu analysieren und sie in die für uns interessanten Felder zu platzieren,
- Mutate – nützlich, um Felder zu manipulieren, Daten zu konvertieren und nicht benötigte Felder zu löschen.
Der Abschnitt output definiert, wohin unsere verarbeiteten Daten gesendet werden sollen. In unserem Fall verwenden wir das Elasticsearch-Plugin, um unsere Daten in der Datenbank zu speichern.
Ich empfehle, sich mit den einzelnen Plugins für jeden Abschnitt vertaut zu machen, da es viele davon gibt und jedes davon sehr interessant ist:
- https://www.elastic.co/guide/en/logstash/current/input-plugins.htmlhttps://
- www.elastic.co/guide/en/logstash/current/filter-plugins.htmlhttps://
- www.elastic.co/guide/en/logstash/current/output-plugins.html
Eine Konfigurationsdatei könnte folgendermaßen aussehen:
input {
file {
path => “/var/log/application.log”
start_position => "beginning"
}
}
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => [
"%{TIMESTAMP_ISO8601:timestamp}%{SPACES}\[%{GREEDYDATA:thread}\]%{SPACES}%{WORD:level}%{SPACES}%{PACKAGE:package}%{SPACES}-%{SPACES}%{GREEDYDATA:log_message}"
]
}
}
date {
match => [ "timestamp", "YYYY-MM-dd HH:mm:ss,SSS" ]
target => "@timestamp"
timezone => "Europe/Warsaw"
}
if [level] == "DEBUG" { drop{} }
mutate {
remove_field => ["timestamp", "time", "host", "@version", "message", "thread"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
}
}
Die obige Konfiguration bewirkt das Lesen aus der Datei application.log. Die Option beginning bedeutet, dass wir die Datei von Anfang an lesen möchten. Dann wird die Datei gefiltert, die Match-Funktion versucht, das Log mit dem angegebenen Muster abzugleichen (die obige Konfiguration gibt über den Parameter patterns_dir den Ort mit definierten benannten Mustern an) und übergibt die Werte an die entsprechenden Felder (timestamp, thread, level, package usw.). Wir möchten, dass unsere Logs Elasticsearch mit dem Datum des Auftretens in der Anwendung erreichen, dazu wird das Plugin date verwendet, dem wir das Datumsformat und das Feld angeben, an das es weitergeleitet werden soll. Das Feld @timestamp wird von Elasticsearch und Kibana standardmäßig verwendet, um Daten nach der Zeit zu indizieren und anzuzeigen. Am Ende dieses Abschnitts löschen wir die nicht benötigten Felder und alle Logs mit der Ebene DEBUG. Im Abschnitt output verwenden wir das Elasticsearch-Plugin, damit die Daten direkt in die Datenbank gelangen.
Als letztes müssen wir Kibana ausführen und index pattern definieren. Wenn wir alle ELK-Elemente korrekt ausgeführt haben, sollten wir zur Auswahl die Elasticsearch-Indizes haben, die uns interessieren.
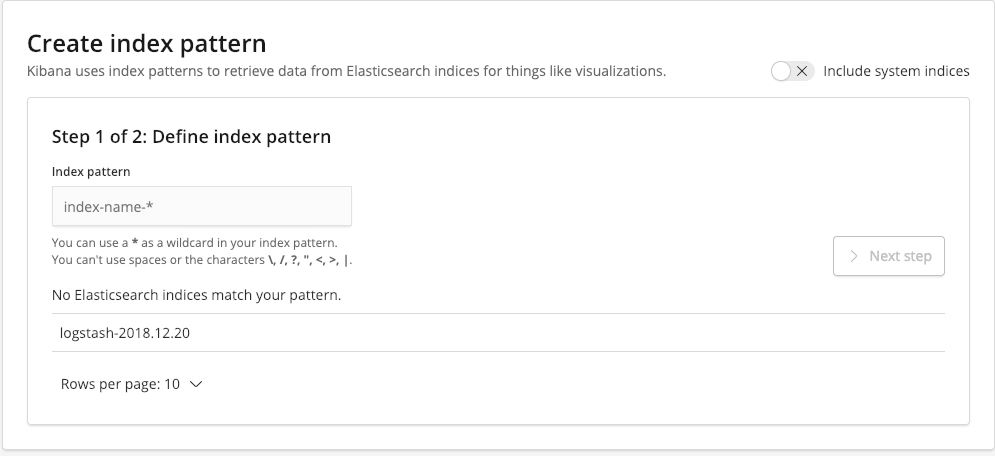
Das Muster ist auf logstash-* gesetzt, wodurch alle Elasticsearch-Indizes erfasst werden, deren Namen mit logstash- beginnen.
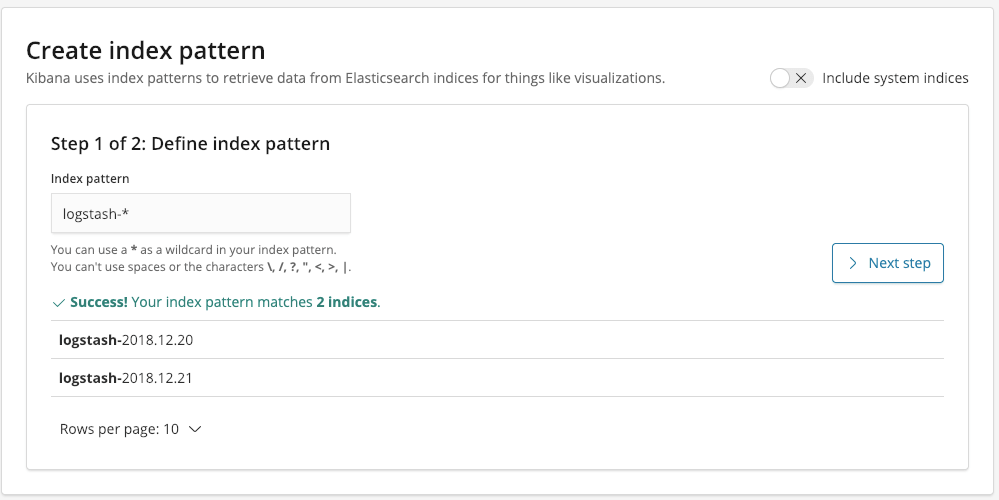
Klicken Sie auf die Schaltfläche Next step. Dann müssen Sie das Feld auswählen, das zum Filtern unserer Daten im Zeitverlauf verwendet wird. In unserem Fall ist dies das Feld @timestamp.
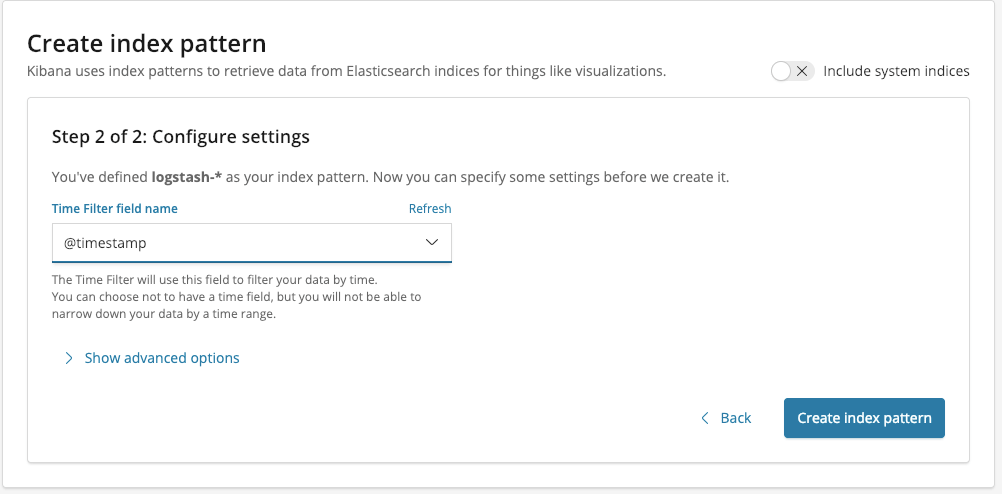
An diesem Punkt können wir das Abenteuer mit der Analyse unserer Daten beginnen. Um die Logs nach vordefinierten Feldern zu durchsuchen, gehen Sie im Seitenmenü auf die Registerkarte Discover.
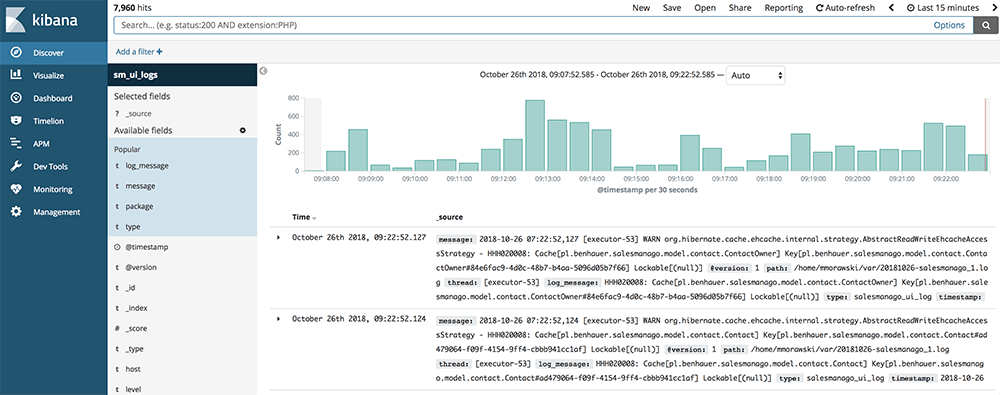
Auf dieser Registerkarte können Sie nach Daten suchen. Dazu können Sie den Zeitraum festlegen und eigene Abfragen eingeben.
Es kommt häufig vor, dass wir die zuvor erstellten Visualisierungen unserer Daten verwenden müssen. Um solche Visualisierungen vorzubereiten, gehen Sie zur Registerkarte Visualize. Zur Auswahl haben wir eine Reihe von Diagrammen und Tools, die uns dabei helfen, unsere Daten zu korrelieren und zu visualisieren. Wir können folgende Diagramme wählen: line, heatmap, pie. Interessant ist das Tool Map, das beim Umgang mit IP-Daten oder geografischen Koordinaten hilfreich ist.
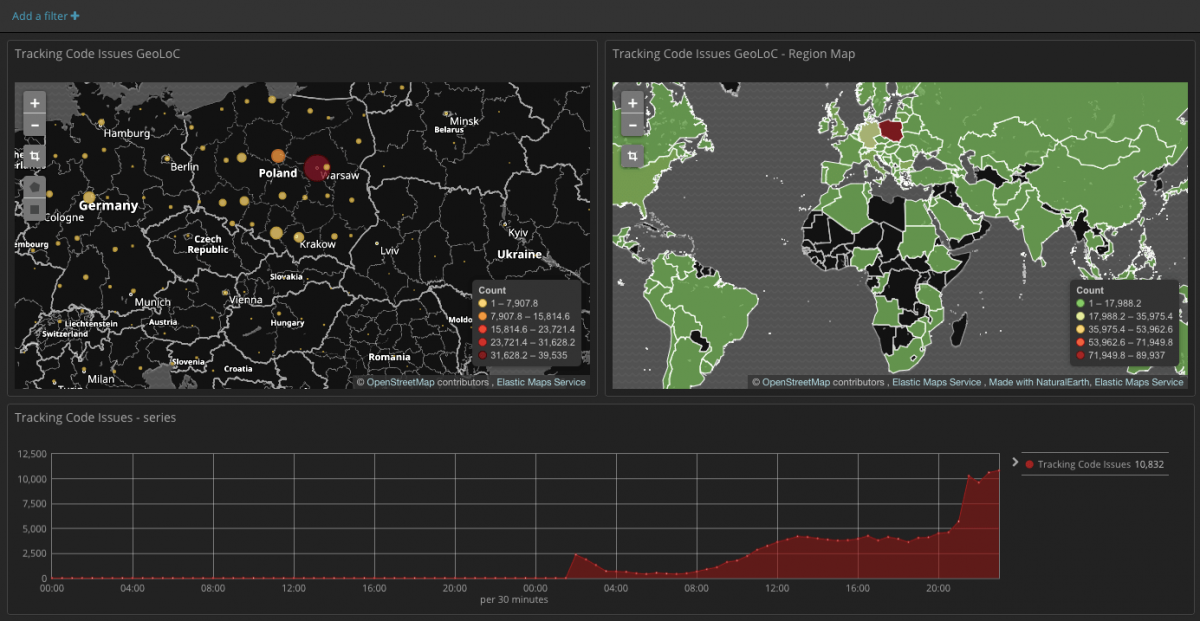
Mit vorgefertigten Visualisierungen können wir Dashboards erstellen, die Informationen enthalten, die uns interessieren. Dadurch ist es sehr einfach, das Verhalten unserer Services zu analysieren.
Ab Version 6.4 stellt uns Kibana auch Werkzeuge für das maschinelle Lernen zur Verfügung. Es bietet Visualisierer, die zum Verständnis der vorhandenen Daten und Werkzeuge beitragen, die unsere Daten auf Anomalien analysieren. Wir werden dieses Tool in einem separaten Artikel vorstellen.
 Follow
Follow




![[NEUE FUNKTIONALITÄT] Ein neuer SaaS-Standard – Human Interface beschleunigt die Navigation um 60 % und erfordert ⅓ weniger Klicks](https://blog.salesmanago.de/wp-content/uploads/2022/02/humnainteraface-sm-de.png)
